Project#
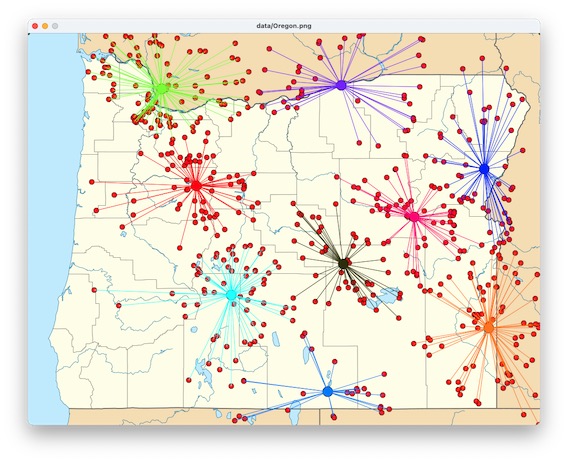
The wildfire clustering project
uses k-means clustering to group wildfire records geographically.
K-means clustering is an example of the successive approximation
computational technique for finding or optimizing a solution to a
problem.
In addition to successive approximation, the wildfire clustering
project uses parallel arrays to represent the evolving set of
clusters, and values in one array (list in Python) as indexes to
other arrays.